You're evaluating AI solutions, and let's be honest, the promises of AI can sometimes feel like a digital mirage – impressive from a distance, but the details are hazy. You know AI holds immense potential for your business, whether it's scaling marketing efforts, streamlining recruiting, or driving enterprise-wide efficiency. But for AI to deliver on its promise, it needs a robust, well-strategized foundation: your data.
This isn't about simply having data; it's about making your data intelligent. As decision-makers, you’re looking for trustworthy insights to navigate the complex world of AI implementation. We're here to provide an authoritative guide, demonstrating how a meticulously crafted data strategy is foundational to AI success, reducing risk, and ensuring your investments pay off.
Why Your AI Rises or Falls on Its Data Strategy
Think of AI as a specialized chef. No matter how skilled, the quality of the meal depends entirely on the ingredients. In AI, those ingredients are your data. Without a solid data strategy, your AI is operating with stale, incomplete, or even misleading information. This doesn't just impact performance; it undermines trust, leads to biased outcomes, and ultimately, wastes resources.
The online food delivery market, projected to hit $1.41 trillion by 2025, offers a prime example. The hyper-personalization and operational efficiencies, like optimized delivery routes and predicted demand, that drive growth in this sector are all powered by sophisticated data strategies and machine learning models. Your business might not be delivering meals, but the principle remains: thoughtful data preparation is key to unlocking AI's transformative power.
Demystifying Your AI Data Choices
Choosing the right approach for your AI data strategy isn't a one-size-fits-all decision. It involves carefully balancing cost, control, and implementation speed. As you evaluate solutions, consider how each factor aligns with your project's unique needs and constraints.
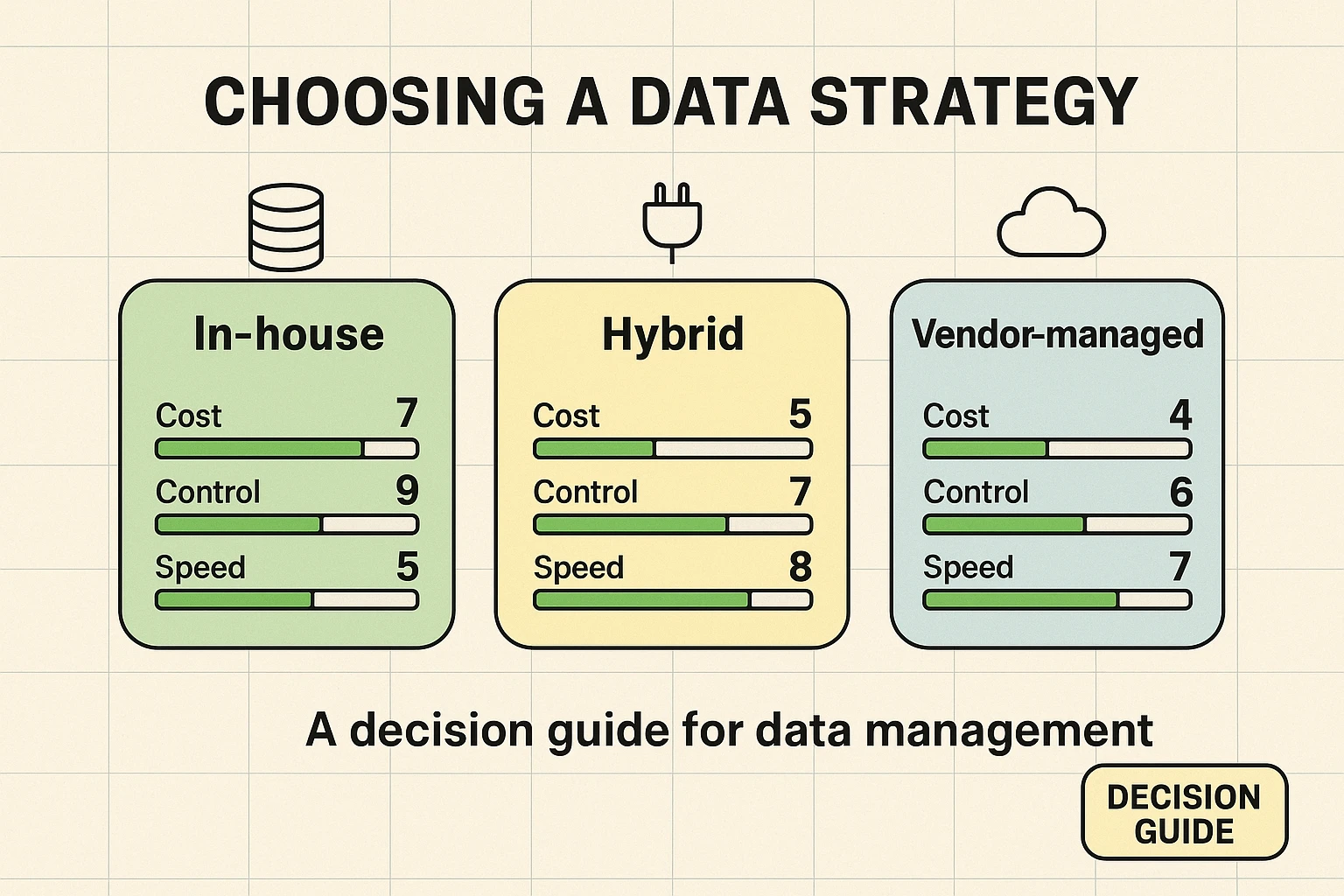
This illustration helps visualize the trade-offs:
- Cost-Optimized: Prioritizes leveraging existing data infrastructure and open-source tools. Offers lower upfront investment but might demand more internal resources and time for customization and maintenance.
- Control-Maximized: Focuses on proprietary systems, bespoke solutions, and maintaining full ownership of data processes. Expensive but offers unparalleled customization and security.
- Speed-Focused: Emphasizes rapid implementation, often utilizing managed services or third-party platforms for quick deployment. Delivers fast results but may involve vendor lock-in or less customization.
Understanding these foundational models helps you articulate your priorities and find a partner that aligns with your strategic objectives.
The Pillars of a Robust AI Data Strategy
Successful AI implementation isn't just about the algorithms; it's intricately tied to how you acquire, manage, and prepare your data. Here's a breakdown of the critical components and why they matter for your AI journey.
1. Data Sourcing: Fueling Your AI Engine
Before an AI model can learn, it needs fuel—data. The first step in any AI initiative is determining where that data comes from. Will you rely on internal databases, external third-party providers, or a combination? The types of data needed for various AI models can vary widely, from structured customer information to unstructured text, images, or time-series data.
Your Evaluation Criteria:
- Variety and Volume: Does the data cover all necessary scenarios for your AI's purpose?
- Veracity: How trustworthy and accurate is the source? Incorrect data sources will lead to incorrect AI decisions.
- Velocity: Can you access and process the data at the speed your AI model requires, especially for real-time applications?
- Value: What is the potential business impact this data unlocks?
2. Data Quality Management: The AI Performance Engine
Garbage in, garbage out. This age-old computing adage is even more critical for AI. Data quality isn't just a best practice; it's a non-negotiable for AI performance. In fact, best practices for AI data pipelines emphasize continuous automated quality checks, deduplication, standardized ingestion, and robust governance. The cost of bad data can be astronomical, leading to failed AI projects, inaccurate predictions, and eroded trust. Conversely, high-quality data directly correlates with higher performing, more reliable AI.
Key Questions to Ask:
- What processes are in place to ensure accuracy, completeness, consistency, timeliness, and validity across all datasets?
- How will data cleansing and deduplication be handled?
- What tools are leveraged for continuous data quality monitoring and remediation?
3. Feature Engineering: Unlocking Deeper Insights
Raw data rarely tells the full story. Feature engineering is the art and science of transforming raw data into features that best represent the underlying problem to the AI model. This can involve combining columns, extracting specific patterns from text, or creating numerical representations of complex data types like images or sound. For instance, in predicting food delivery time, features might include traffic conditions, restaurant preparation time, and delivery distance. Effective feature engineering dramatically impacts model interpretability and predictive performance.
Considerations for Your Solution:
- How will the solution leverage existing domain expertise to create relevant features?
- Is there support for automated feature engineering (AutoML) to expedite the process and explore diverse features?
4. Data Labeling Strategies: Teaching Your AI Smarter
For most supervised learning AI models, high-quality labeled data is indispensable. This means human annotators (or programmatic tools) tagging data to teach the AI what to look for. Whether it's identifying objects in an image, categorizing customer feedback, or marking entities in a document, accurate labeling directly determines how well an AI model learns and performs.
Decision Factors:
- Accuracy vs. Cost: How will the labeling strategy balance budget constraints with the need for highly accurate labels? Options range from manual in-house labeling to crowdsourcing or specialized labeling services.
- Ethical Considerations: Are there ethical guidelines in place for labeling sensitive data and ensuring fairness in annotation?
5. Establishing Data Pipelines: Your Continuous AI Supply Chain
No AI model is a static entity. It requires a continuous, reliable supply of data to learn, adapt, and maintain relevance. Robust data pipelines are the infrastructure that moves, transforms, and delivers data from its source to your AI models. These pipelines must be scalable, resilient, and capable of handling both batch processing and real-time data streams, depending on your AI's operational needs.
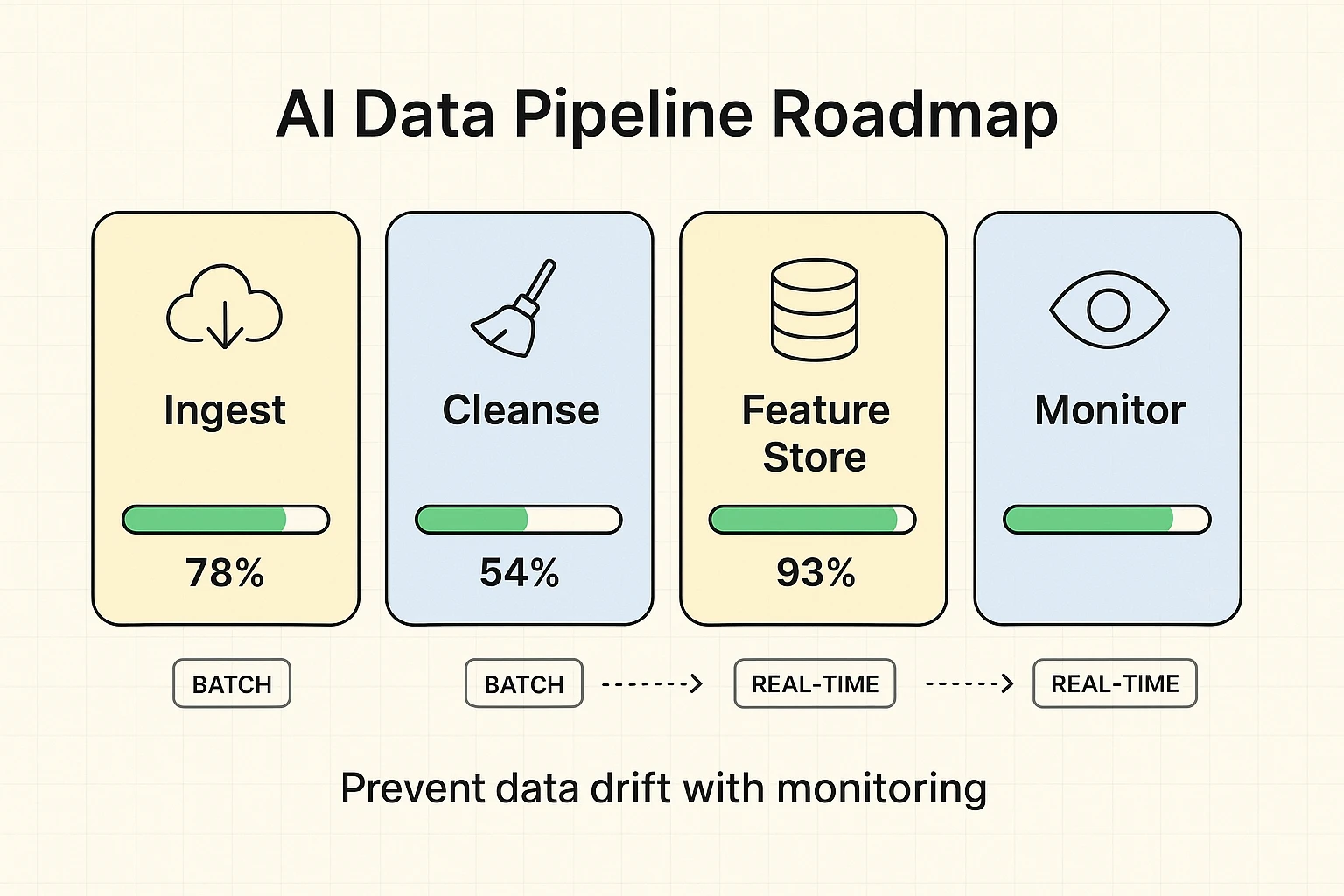
This roadmap helps you understand the different stages and maturity levels of data pipelines. For instance, a batch pipeline is suitable for models that don’t require instantaneous updates (like monthly marketing reports), while real-time pipelines are crucial for applications requiring immediate data processing (like fraud detection or AI SEO automation workflows). Ensuring continuous data flow is vital to prevent data drift, where a model's performance degrades over time due to changes in real-world data patterns.
Beyond the Basics: Advanced Strategies for Trustworthy AI
As you deepen your AI evaluation, certain advanced data strategies become crucial, distinguishing true AI-first businesses from those merely experimenting.
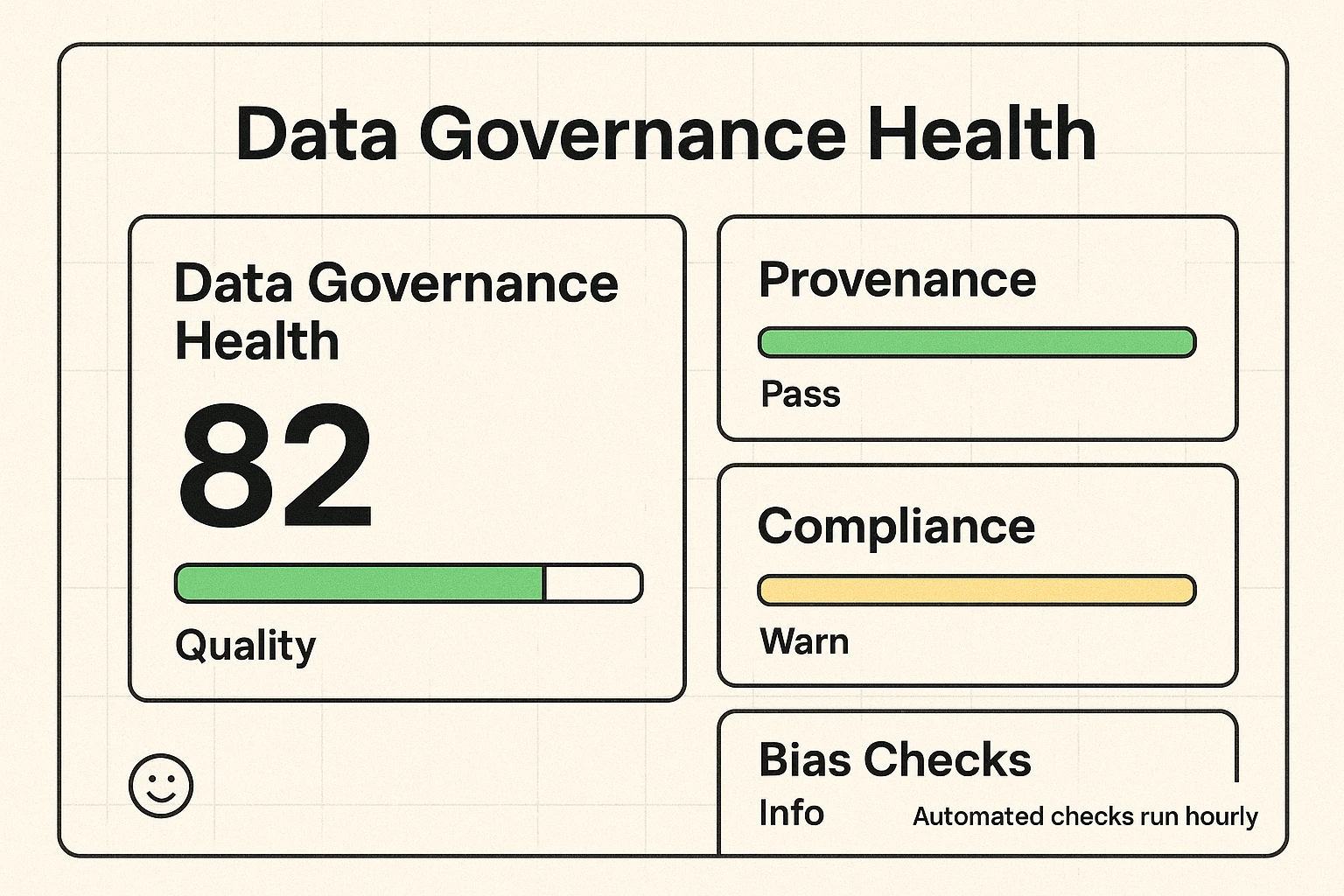
6. Data Governance for AI: Building Trust and Compliance
In an age of increasing regulation (like GDPR and the upcoming AI Act), robust data governance isn't optional—it's foundational. For AI, this means establishing clear policies for data access, usage, retention, and deletion. It's about ensuring your AI outputs are explainable, ethical, and compliant. Legislatures are already promoting harm evaluations and independent audits of AI models, emphasizing the need for tools like refutation in AI to detect and mitigate bias.
Checklist for Evaluation:
- Does the proposed solution integrate with or provide frameworks for data governance policies?
- How does it support regulatory compliance for AI-driven processes?
This compliance dashboard offers a snapshot of data health, providing clear metrics and checks for privacy and regulatory adherence. It helps you quickly assess if an AI solution meets your governance requirements and builds confidence in its ethical deployment.
7. Synthetic Data Generation: Innovating with Privacy
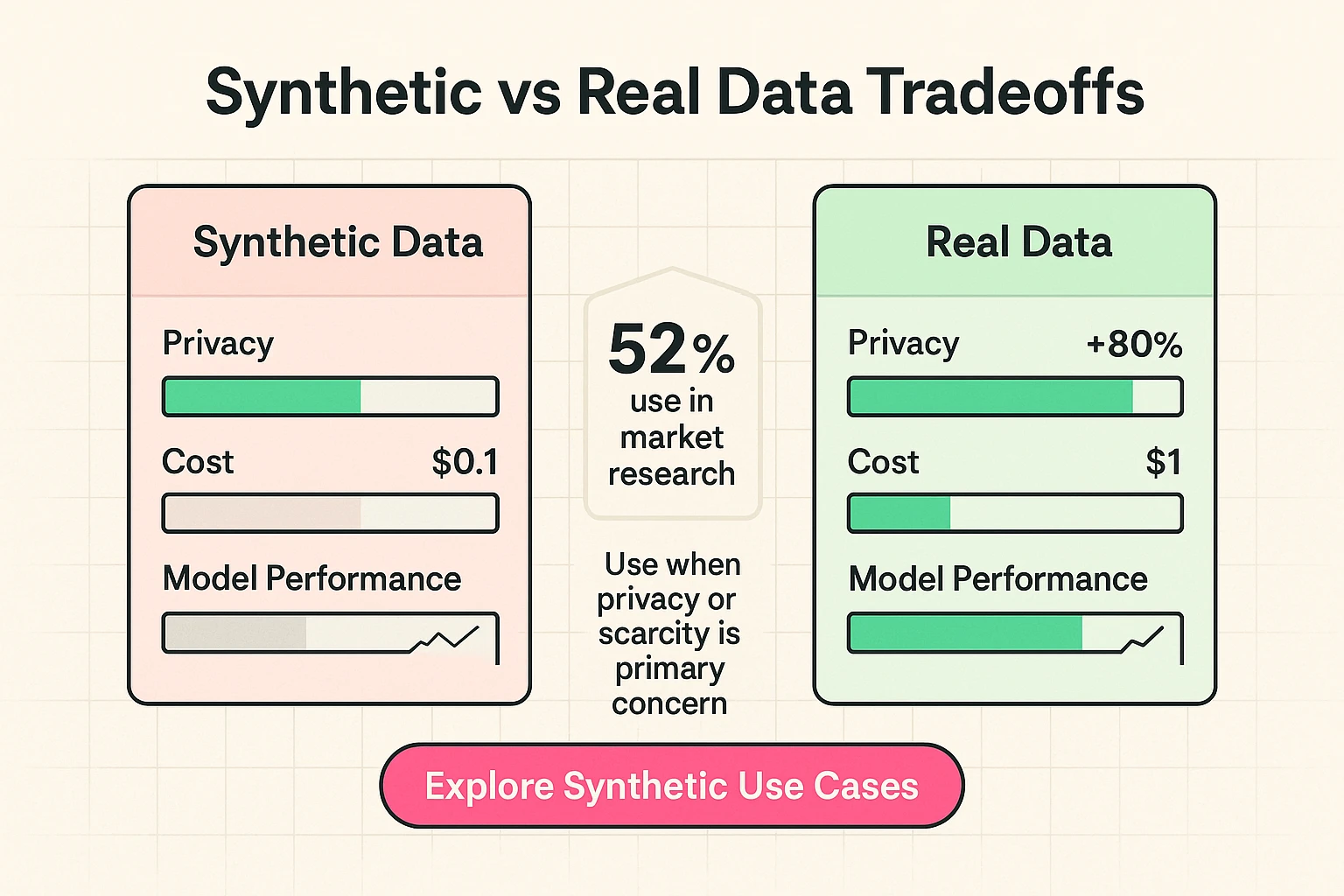
Imagine developing advanced AI models without compromising the privacy of real individuals, or acquiring data for rare events that barely exist. This is where synthetic data comes in. Synthetic data is artificially generated data that mirrors the statistical properties of real data but contains no actual personal information. It's becoming a game-changer, with 52% of market researchers already using it as a full replacement for human input in some cases. It addresses critical issues like privacy, data scarcity, and bias mitigation.
The Synthetic Data Advantage:
- Privacy Preservation: Train AI models on sensitive data without exposing private information.
- Data Augmentation: Generate more data for scarce events or under-represented groups, improving model robustness and fairness.
- Cost Efficiency: Reduce the cost and complexity of real-world data collection and anonymization.
- Bias Mitigation: Create balanced datasets to counteract biases present in real-world data.
This visual comparison highlights the trade-offs between synthetic and real data across privacy, cost, and performance metrics. It's a key decision point for many businesses. For instance, synthetic data can improve medical imaging accuracy to 85.9% when combined with actual data. Understanding when to incorporate synthetic data is a powerful strategic advantage for ethical and high-performing AI.
8. Privacy-Preserving AI Techniques: Ethical by Design
Beyond synthetic data, other advanced techniques like homomorphic encryption, federated learning, and differential privacy allow AI models to learn from sensitive data without ever directly accessing or revealing the raw information. These techniques are crucial for building trust, especially in industries with strict data protection requirements like healthcare or finance. When evaluating AI solutions, differentiating based on these privacy guarantees becomes paramount.
Points of Differentiation:
- Does the solution offer support for privacy-preserving AI to meet stringent data protection requirements?
- How does it enable collaboration and learning across decentralized datasets while maintaining privacy?
9. Managing Data Lifecycles for ML Models: Sustainable AI
AI models aren't "set it and forget it." Data changes over time, and your models must adapt. Managing the data lifecycle for machine learning models involves strategies for data versioning, lineage tracking (understanding where data came from and how it was processed), continuous model monitoring, and retraining. This ensures your AI models remain relevant and effective over the long term, preventing issues like model decay and unexpected performance drops. Considerations like AI-powered SEO reporting dashboards and AI keyword and content gap analysis rely on continuous data input to maintain their accuracy and utility.
Long-Term Strategy Focus:
- What mechanisms are in place for data versioning and tracking changes to source data?
- How does the solution support continuous monitoring of data and model performance, triggering retraining as needed?
FAQs: Addressing Your Key Concerns
Q1: What’s the biggest risk if we skimp on data preparation?
A: The biggest risk is developing an AI system that is unreliable, biased, or simply doesn't deliver on its intended purpose. Bad data leads to bad AI. This can result in financial losses, reputational damage, and wasted resources. It also fundamentally erodes trust in your AI outputs, making adoption within your organization far more challenging.
Q2: How can we tell if a vendor truly understands AI data strategy, versus just offering generic AI tools?
A: Look for specificity. A true expert will discuss data sourcing (internal vs. external, types of data), data quality metrics (accuracy, completeness), feature engineering techniques specific to your domain, and advanced topics like synthetic data or privacy-preserving AI. They'll also emphasize an end-to-end data pipeline and a robust data governance framework. Be wary of solutions that focus solely on the model without deep consideration for the data fueling it.
Q3: We have a lot of legacy data. Is it feasible to use it for AI?
A: Absolutely, but it requires careful strategy. Legacy data often contains inconsistencies, missing values, or outdated formats. A strong data preparation strategy involves profiling this data, cleansing it, transforming it into usable formats, and potentially augmenting it with newer, more relevant sources. The goal is to maximize the value of your existing assets while addressing their inherent challenges. We specialize in helping businesses integrate diverse data sources into coherent AI systems.
Q4: How do we balance data privacy regulations with the need for rich datasets for AI?
A: This is a critical challenge, and it's driving the adoption of advanced techniques. Solutions like synthetic data generation, federated learning, homomorphic encryption, and differential privacy are specifically designed to allow AI to learn from sensitive data without compromising privacy. A robust AI data strategy will include these privacy-preserving methods as core components, not afterthoughts.
Q5: What's the ROI of investing heavily in data strategy and preparation upfront?
A: The ROI is significant. By ensuring high-quality, well-prepared data from the start, you dramatically increase the chances of your AI models performing effectively, reducing development cycles, minimizing costly errors, and accelerating time to value. It mitigates the risk of needing expensive reworks or, worse, a complete project failure. It also builds trust in your AI, fostering greater adoption and long-term success. Think of it as investing in the foundation of a skyscraper; a weak foundation means a weak building.
Build Your AI Advantage with a Trusted Partner
Developing a high-performance AI system doesn't happen by chance. It's the result of a meticulously planned and executed data strategy – from sourcing and quality to advanced privacy techniques and lifecycle management. At BenAI, we understand that you're not just looking for an AI vendor; you're looking for a partner who can navigate this complexity with you.
We provide the expertise to transform your raw information into intelligent data, powering AI solutions that drive real growth and efficiency. Whether you're a marketing agency aiming to scale lead generation with AI like LinkedIn lead generation with AI automation, a recruiting firm optimizing its hiring process, or an enterprise seeking comprehensive AI transformation, your success begins with a robust data foundation.
Ready to architect an AI data strategy that truly empowers your business? Let's discuss your specific needs and build a tailored plan.
Join Our Growing AI Business Community
Get access to our AI Automations templates, 1:1 Tech support, 1:1 Solution Engineers, Step-by-step breakdowns and a community of forward-thinking business owners.

Latest Blogs
Explore our latest blog posts and insights.